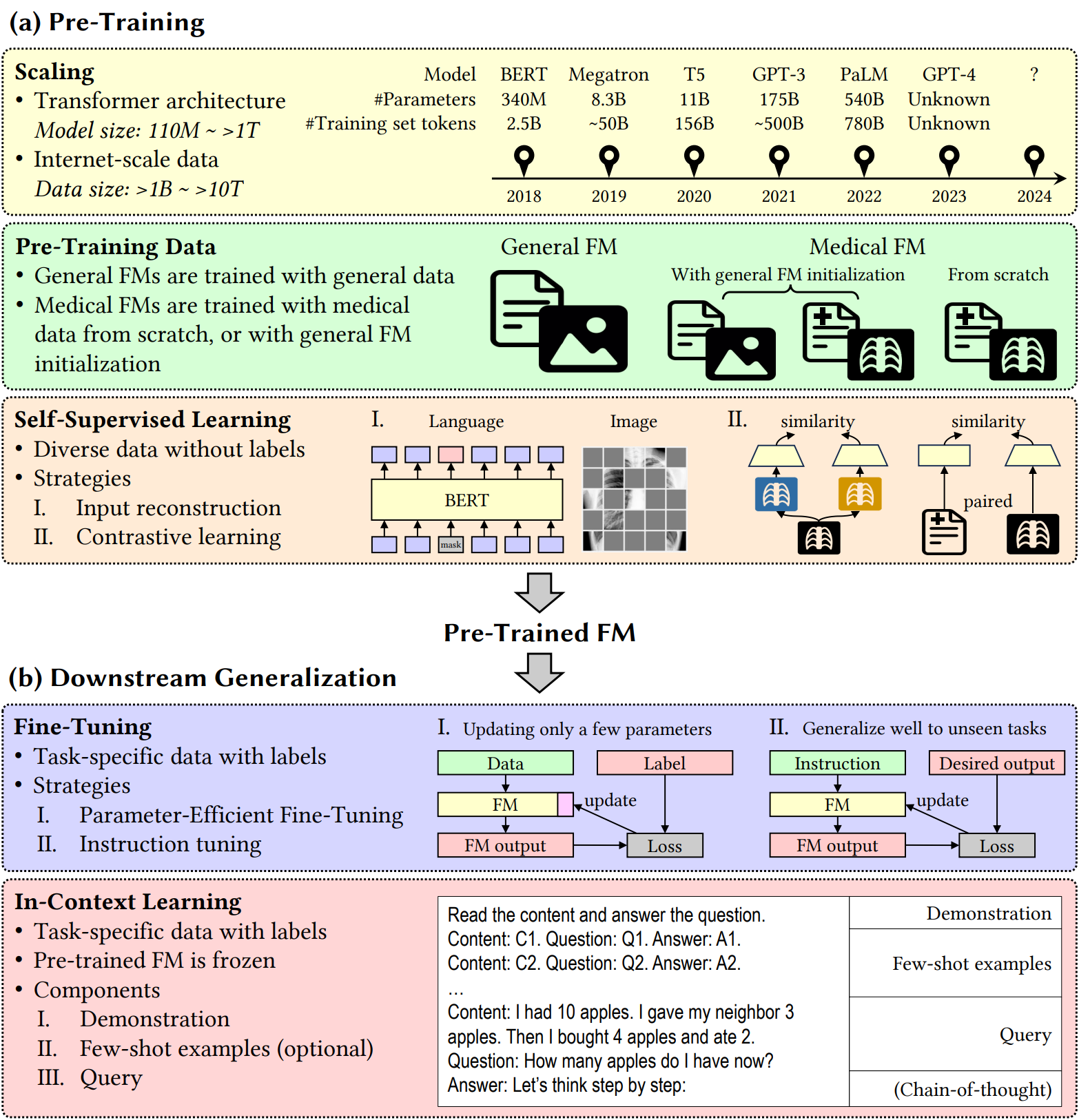
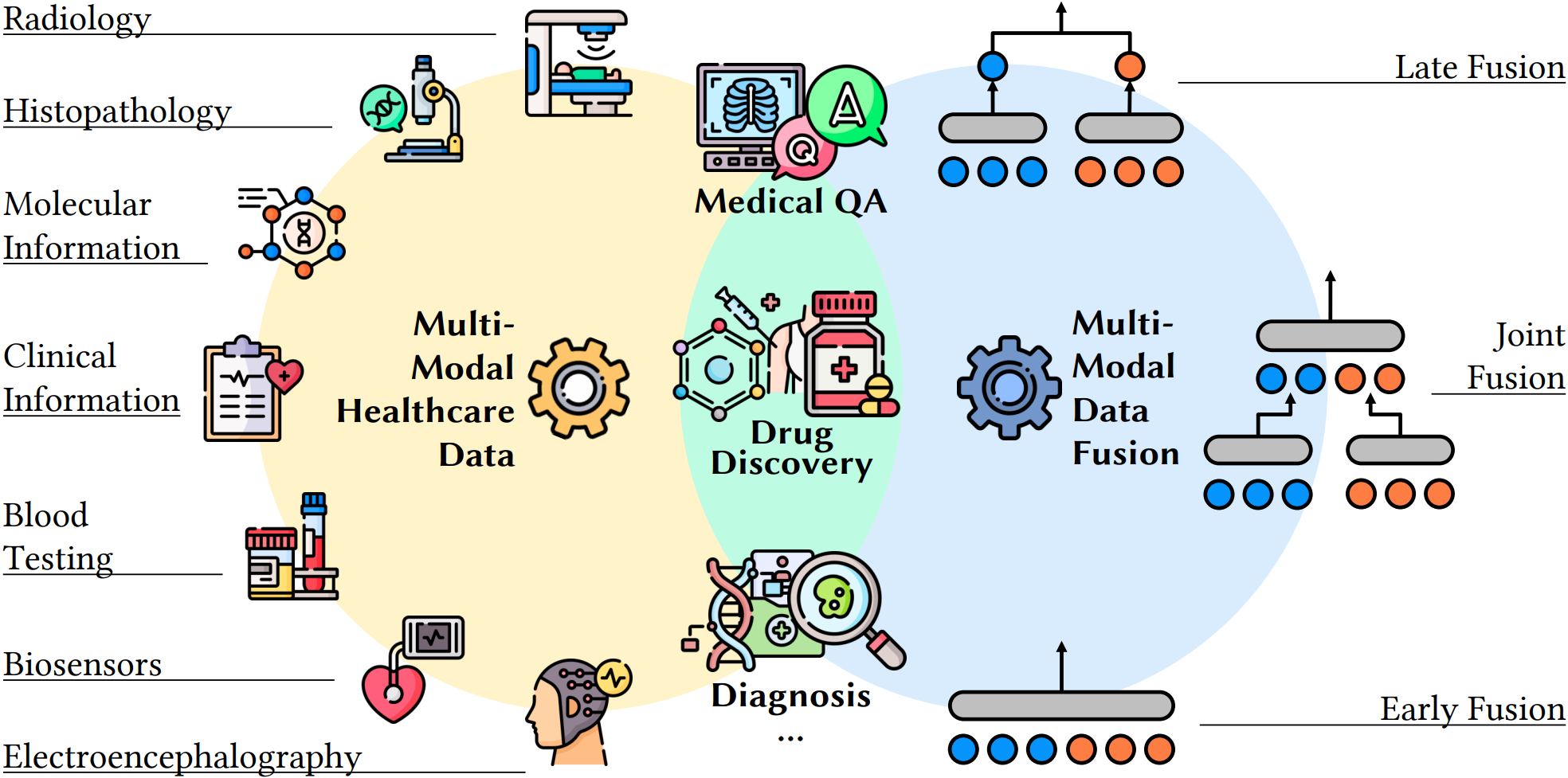
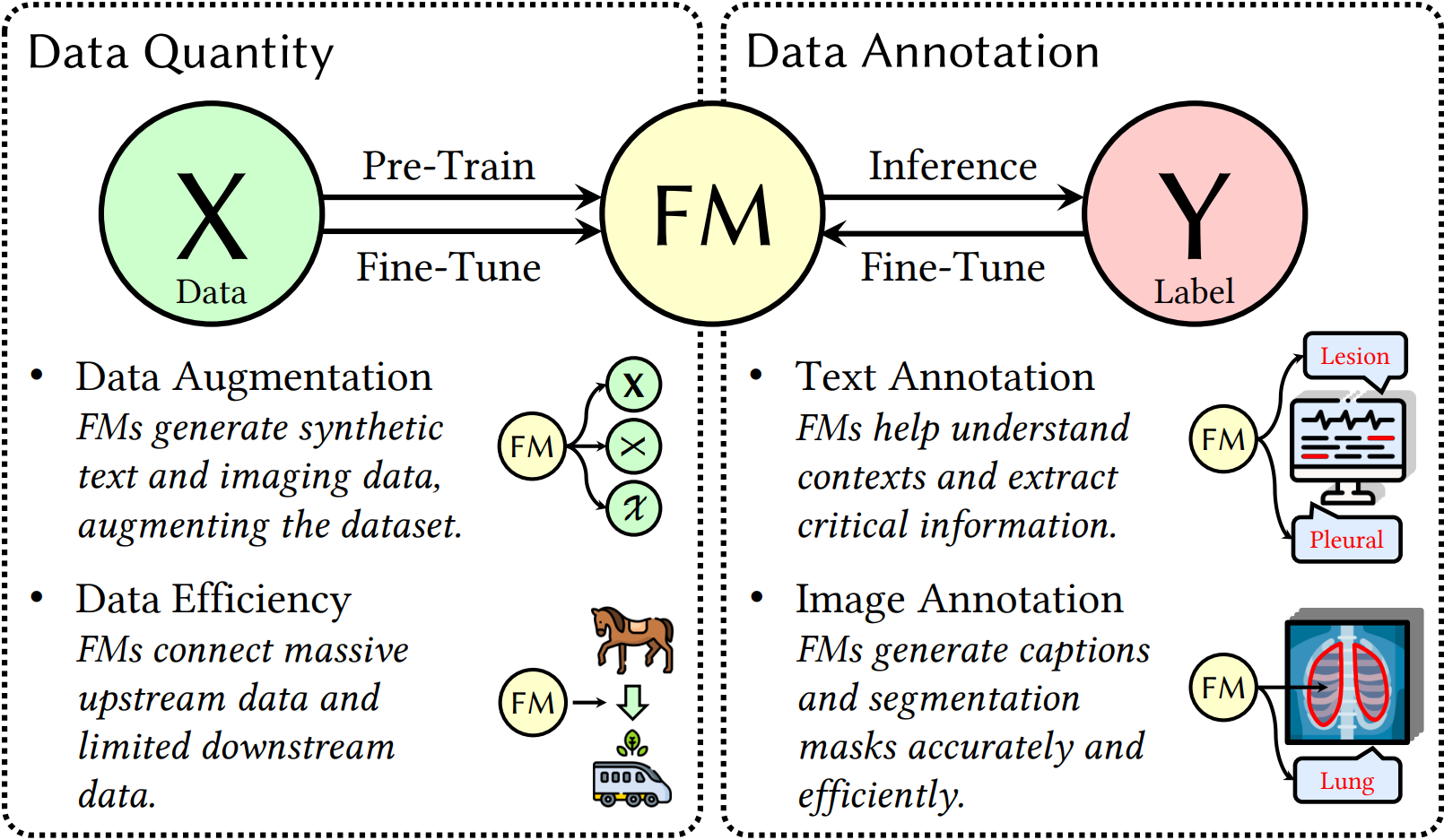
Overview
From a data-centric viewpoint, we emphasize the interplay between patients, healthcare data, and foundation models. Patients generate healthcare data and interact with foundation models. Healthcare data captures patient characteristics and supports foundation model training, inference, and deployment. Foundation models assess healthcare data and benefit patients. As illustrated, data-centric strategies promise to reshape clinical workflow , enable precise diagnosis, and uncover insights into treatment.
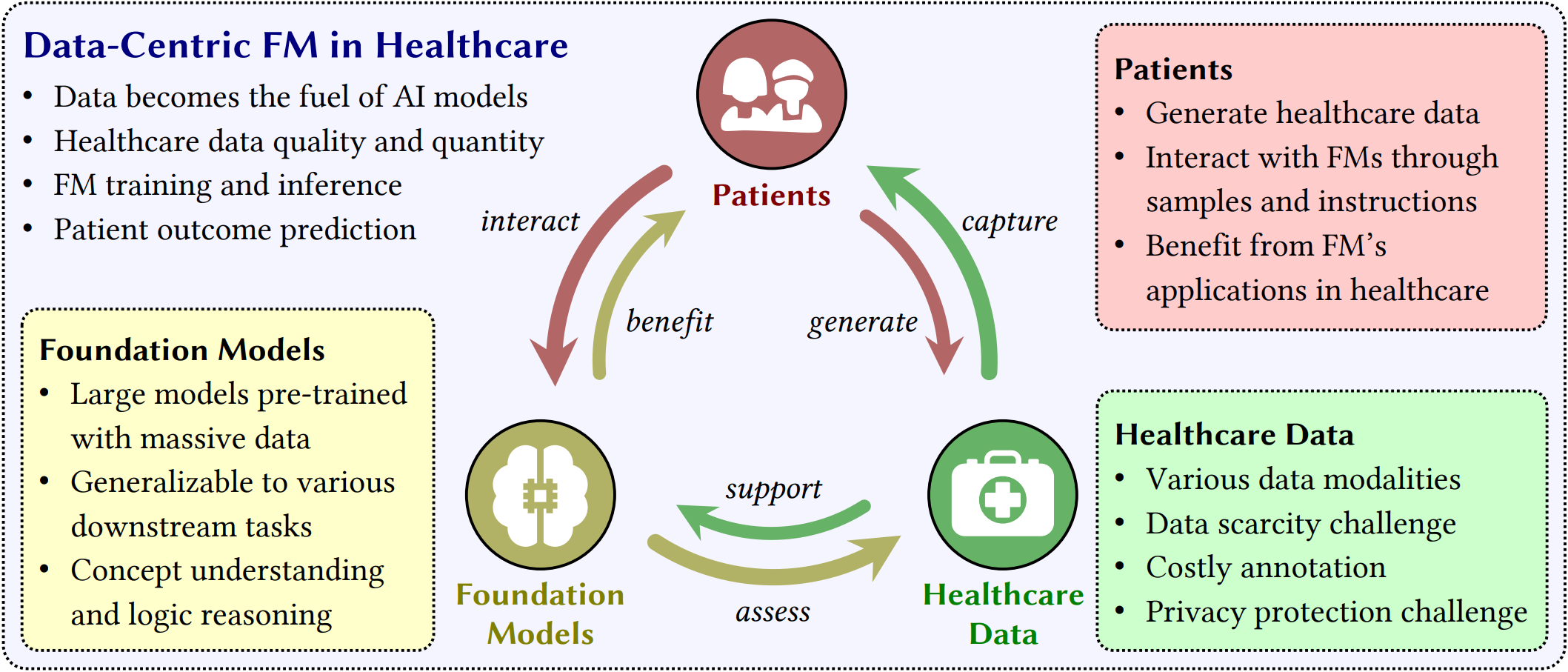
Why data-centric?
- Foundation models demonstrate the power of scale, where the enlarged model and data size permit foundation models to capture vast amounts of information, thus increasing the pressing need of training data quantity.
- Foundation models encourage homogenization as evidenced by their extensive adaptability to downstream tasks. High-quality data for foundation model training thus becomes critical since it can impact the performance of both pre-trained and downstream models.
In healthcare
Healthcare and medical data challenges have posed persistent obstacles over decades, including multi-modality data fusion, limited data volume, annotation burden, and the critical concern of patient privacy protection. To respond, the foundation model era opens up perspectives to advance data-focused AI analytics in healthcare.